eBPF:Redemption
由于本人刚打通大表哥结局,十分感伤,因此文章标题与内容没有任何联系:’(
第一章:犁刀村
介绍eBPF之前,有必要了解一下他的前身,也就是BPF(Berkeley Packet Filter),现在为了同eBPF(external BPF)区分开来被称作cBPF(classic BPF)
伯克利包过滤器(英语:Berkeley Packet Filter,缩写 BPF),是类Unix系统上数据链路层的一种原始接口,提供原始链路层数据包的收发。除此之外,如果网卡驱动支持混杂模式,那么它可以让网卡处于此种模式,这样可以收到网络上的所有包,不管他们的目的地是不是所在主机。
另外,BPF支持过滤数据包——用户态的进程可以提供一个过滤程序来声明它想收到哪些数据包。通过这种过滤可以避免从操作系统内核向用户态复制其他对用户态程序无用的数据包,从而极大地提高性能。
从3.18版本开始,Linux 内核提供了一种扩展的BPF虚拟机,被称为“extended BPF”,简称为eBPF。它能够被用于非网络相关的功能,比如附在不同的tracepoints上,从而获取当前内核运行的许多信息。
传统的BPF,现在被称为cBPF(classical BPF)。
eBPF由Alexei Starovoitov在PluMgrid工作时设计,这家公司专注于研究新的方法来设计软件定义网络解决方案。在它只是一个提议时,Daniel Borkmann——Red Hat公司的内核工程师,帮助修改使得它能够进入内核代码并完全替代已有的BPF实现。这是二十年来BPF首次主要的更新,使得BPF成为了一个通用的虚拟机。
eBPF被Linux内核合并的事件线如下
- 2014年3月。eBPF补丁被合并到Linux内核。
- 2014年6月。JIT组件被合并到内核3.15版本。
- 2014年12月。bpf系统调用被合并到内核3.18版本。
- 在后来的Linux 4.x系列版本中又添加了对于kprobes、uprobes、tracepoints以及perf_events的支持。
因为eBPF虚拟机使用的是类似于汇编语言的指令,对于程序编写来说直接使用难度非常大。和将C语言生成汇编语言类似,现在的编译器正在逐步完善从更高级的语言生成BPF虚拟机使用的指令。LLVM在3.7版本开始支持BPF作为后端输出。GCC 10也将会支持BPF作为后端。BCC是IOVisor项目下的编译器工具集,用于创建内核跟踪(tracing)工具。bpftrace是为eBPF设计的高级跟踪语言,在Linux内核(4.x)中提供。
eBPF现在被应用于网络、跟踪、内核优化、硬件建模等领域。
以下类容大部分来自于linux官方手册
eBPF is designed to be JITed with one to one mapping, which can also open up the possibility for GCC/LLVM compilers to generate optimized eBPF code through an eBPF backend that performs almost as fast as natively compiled code.
这里告诉我们eBPF被设计为一对一映射的动态翻译,这也使得GCC/LLVM编译器通过后端eBPF产生优化eBPF代码成为可能,从而能达到原生编译代码一样的运行速度
1.cBPF to eBPF
cBPF到eBPF有以下几种变化(这里仅列出个人认为适合当下自身学习的部分)
寄存器从2个增加了10个
旧格式有两个寄存器A和X,以及一个隐藏帧指针。新布局将其扩展到 10 个内部寄存器和一个只读帧指针。所有 eBPF 寄存器都一对一映射到 x86_64、aarch64 等上的硬件寄存器,并且 eBPF 调用约定直接映射到 64 位架构上内核使用的 ABI。并且之恩能够有一个eBPF程序,也就是说唯一一个eBPF主线程,并且他不能调用其他eBPF函数,它只能调用预定义的内核函数
1
2
3
4
5
6
7
8
9
10
11R0 - rax
R1 - rdi
R2 - rsi
R3 - rdx
R4 - rcx
R5 - r8
R6 - rbx
R7 - r13
R8 - r14
R9 - r15
R10 - rbp在内核函数调用之前,eBPF 程序需要将函数参数放入 R1 到 R5 寄存器中以满足调用约定,然后解释器将从寄存器中取出它们并传递给内核函数。如果 R1 - R5 寄存器映射到用于在给定架构上传递参数的 CPU 寄存器,则 JIT 编译器不需要发出额外的移动。函数参数将位于正确的寄存器中,并且 BPF_CALL 指令将被 JIT 为单个“调用”硬件指令。选择此调用约定是为了涵盖常见的调用情况,而不会影响性能。
在内核函数调用之后,R1 - R5 被重置为不可读,并且 R0 具有函数的返回值。由于 R6 - R9 是被调用者保存的,因此它们的状态在整个调用过程中都会保留。
这里需要注意每一个eBPF程序都会有且只有一个自带的参数
ctx,他默认保存在R1当中
eBPF重用了经典的大部分操作码编码,以简化cBPF到eBPF的转换
对于算术和跳转指令,8位代码字段分为三个部分
1 | |
其中LSB的3bits存储着指令的类别:
| Classic BPF classes | eBPF classes |
|---|---|
| BPF_LD 0x00 | BPF_LD 0x00 |
| BPF_LDX 0x01 | BPF_LDX 0x01 |
| BPF_ST 0x02 | BPF_ST 0x02 |
| BPF_STX 0x03 | BPF_STX 0x03 |
| BPF_ALU 0x04 | BPF_ALU 0x04 |
| BPF_JMP 0x05 | BPF_JMP 0x05 |
| BPF_RET 0x06 | BPF_JMP32 0x06 |
| BPF_MISC 0x07 | BPF_ALU64 0x07 |
而第四位表示编码源操作数
1 | |
然后MSB的高四位存储操作代码:
如果说instruction class 是 BPF_ALU或者 BPF_ALU64[in eBPF],则该操作码为以下之一:
1
2
3
4
5
6
7
8
9
10
11
12
13
14BPF_ADD 0x00
BPF_SUB 0x10
BPF_MUL 0x20
BPF_DIV 0x30
BPF_OR 0x40
BPF_AND 0x50
BPF_LSH 0x60
BPF_RSH 0x70
BPF_NEG 0x80
BPF_MOD 0x90
BPF_XOR 0xa0
BPF_MOV 0xb0 /* eBPF only: mov reg to reg */
BPF_ARSH 0xc0 /* eBPF only: sign extending shift right */
BPF_END 0xd0 /* eBPF only: endianness conversion */如果说instruction class 是 BPF_JMP或者 BPF_JMP32[in eBPF],则该操作码为以下之一:
1
2
3
4
5
6
7
8
9
10
11
12
13
14BPF_JA 0x00 /* BPF_JMP only */
BPF_JEQ 0x10
BPF_JGT 0x20
BPF_JGE 0x30
BPF_JSET 0x40
BPF_JNE 0x50 /* eBPF only: jump != */
BPF_JSGT 0x60 /* eBPF only: signed '>' */
BPF_JSGE 0x70 /* eBPF only: signed '>=' */
BPF_CALL 0x80 /* eBPF BPF_JMP only: function call */
BPF_EXIT 0x90 /* eBPF BPF_JMP only: function return */
BPF_JLT 0xa0 /* eBPF only: unsigned '<' */
BPF_JLE 0xb0 /* eBPF only: unsigned '<=' */
BPF_JSLT 0xc0 /* eBPF only: signed '<' */
BPF_JSLE 0xd0 /* eBPF only: signed '<=' */
因此这里举例子 bpf指令BPF_ADD|BPF_X|BPF_ALU在cBPF和eBPF中都表示经典32位加法。cBPF中只有两个寄存器,意味着A+=X。而在eBPF中意味着dst_reg = (u32)dst_reg + (u32)src_reg
cBPF使用BPF_MISC类来表示A=X和X=A移动,eBPF则使用 BPF_MOV |BPF_X|BPF_ALU来表示。eBPF中将类别7用作BPF_ALU64,这里等价于BPF_ALU但是是使用64为操作数。
经典 BPF 浪费了整个 BPF_RET 类来表示单个 ret 操作。经典 BPF_RET | BPF_K表示将imm32复制到返回寄存器并执行函数退出。 eBPF 被建模为匹配 CPU,因此 BPF_JMP|BPF_EXIT在eBPF中表示函数退出。 eBPF 程序需要在执行 BPF_EXIT 之前将返回值存储到寄存器 R0 中。 eBPF 中的第 6 类用作 BPF_JMP32,表示与 BPF_JMP 完全相同的操作,但使用 32 位宽的操作数进行比较。
而对于加载和存储指令指令,8位代码字段分为三个部分
1 | |
size字段如下:
1 | |
mode字段如下:
1 | |
2.eBPF的基本架构
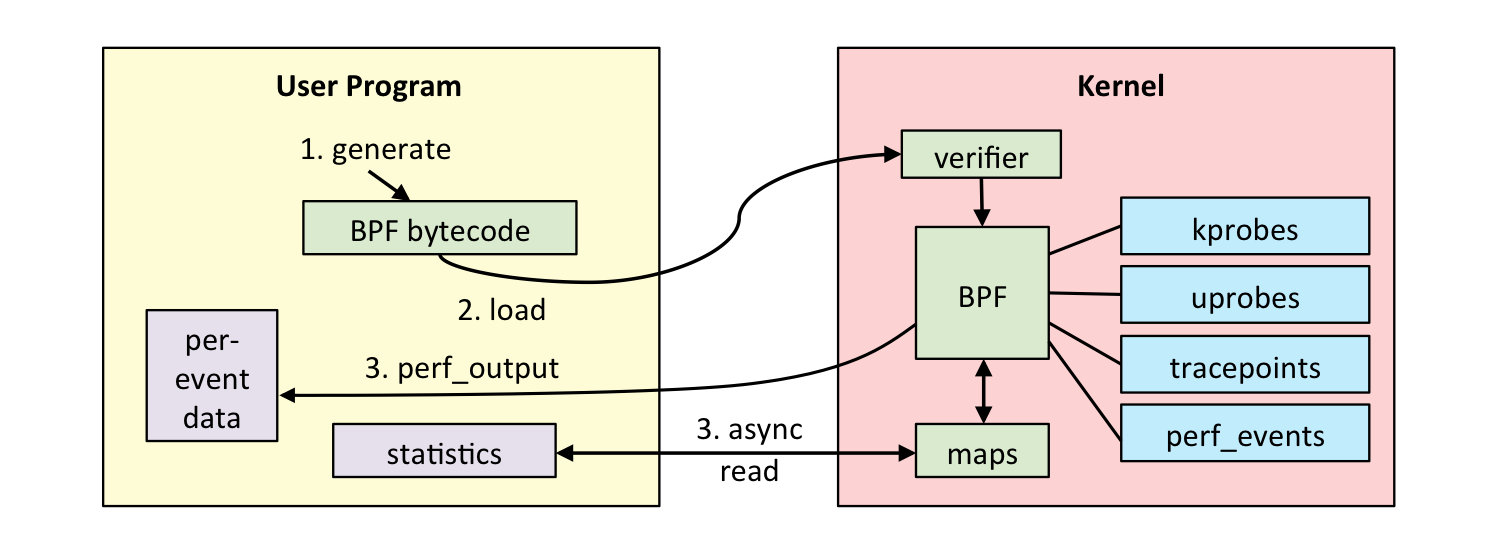
上图为eBPF的一个经典图,其中也是显示了一个eBPF程序的运行过程:
- 用户自行产生BPF字节码
- 将该字节码加载到内核空间
- 内核空间的eBPF verifier 对字节码程序进行检查,通过检查后进行JIT编译
- 程序当中可能会创建内核同用户交互的eBPF maps
下面是man手册当中的eBPF程序、maps与绑定事件之间的映射关系
1 | |
第二章:马掌望台
这一章我将直接从man手册中以及linux源码当中分析
1 | |
1.eBPF maps 概述
BPF map可以通过bpf系统调用来进行读写
下面介绍与bpf系统调用相关的参数:
cmd:
BPF_MAP_CREATE:创建一个map并且返回一个指向该map的文件描述符BPF_MAP_LOOKUP_ELEM:通过给定的key在指定的map当中寻找元素,并且返回他的值BPF_MAP_UPDATE_ELEM:创建或者更新一个元素(当然也是给定key在指定map当中寻找)BPF_MAP_DELETE_ELEM:删除元素BPF_AP_GET_NEXT_KEY:寻找给定key的下一个元素BPF_PROG_LOAD:验证且加载一个eBPF程序,返回一个与该程序关联的文件描述符
attr:
他指向一个bpf_attr结构体,他的结构如下(由于linux 6.7源码当中过大,所以这里仅给出手册给出的版本,应该是很具有代表性的
1 | |
maps 是一个存放不同类型数据的数据结构体,他可以在不同的eBPF内核程序内共享数据,同样可以使得内核和用户应用间共享。接下来详细介绍每个字段的使用
2.BPF_MAP_CREATE
示例
1 | |
这里直接讲解其中所涉及到的源码部分,在系统调用判定cmd之前会有一些安全性的检查,这里我们先掠过,等到基础扎实了再进行了解
1 | |
所以直接看到下面代码
1 | |
可以看到其中有很多map_type,他是集成到attr里面的,他在源码当中以enum类型来定义
1 | |
最后给出创建的bpf_map
1 | |
第三章:克莱蒙斯据点
1.eBPF program 概述
The BPF_PROG_LOAD command is used to load an eBPF program into the kernel. The return value for this command is a new file descriptor associated with this eBPF program.
1 | |
下面来解释每个字段的含义
prog_type:
根据linux手册的说法,在内核版本4.4之后非特权用户只能使用
BPF_PROG_TYPE_SOCKET_FILTERUnprivileged access may be blocked by writing the value 1 to the file /proc/sys/kernel/unprivileged_bpf_disabled.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44/* include/uapi/linux/bpf.h */
956 /* Note that tracing related programs such as
957 * BPF_PROG_TYPE_{KPROBE,TRACEPOINT,PERF_EVENT,RAW_TRACEPOINT}
958 * are not subject to a stable API since kernel internal data
959 * structures can change from release to release and may
960 * therefore break existing tracing BPF programs. Tracing BPF
961 * programs correspond to /a/ specific kernel which is to be
962 * analyzed, and not /a/ specific kernel /and/ all future ones.
963 */
964 enum bpf_prog_type {
965 BPF_PROG_TYPE_UNSPEC,
966 BPF_PROG_TYPE_SOCKET_FILTER,
967 BPF_PROG_TYPE_KPROBE,
968 BPF_PROG_TYPE_SCHED_CLS,
969 BPF_PROG_TYPE_SCHED_ACT,
970 BPF_PROG_TYPE_TRACEPOINT,
971 BPF_PROG_TYPE_XDP,
972 BPF_PROG_TYPE_PERF_EVENT,
973 BPF_PROG_TYPE_CGROUP_SKB,
974 BPF_PROG_TYPE_CGROUP_SOCK,
975 BPF_PROG_TYPE_LWT_IN,
976 BPF_PROG_TYPE_LWT_OUT,
977 BPF_PROG_TYPE_LWT_XMIT,
978 BPF_PROG_TYPE_SOCK_OPS,
979 BPF_PROG_TYPE_SK_SKB,
980 BPF_PROG_TYPE_CGROUP_DEVICE,
981 BPF_PROG_TYPE_SK_MSG,
982 BPF_PROG_TYPE_RAW_TRACEPOINT,
983 BPF_PROG_TYPE_CGROUP_SOCK_ADDR,
984 BPF_PROG_TYPE_LWT_SEG6LOCAL,
985 BPF_PROG_TYPE_LIRC_MODE2,
986 BPF_PROG_TYPE_SK_REUSEPORT,
987 BPF_PROG_TYPE_FLOW_DISSECTOR,
988 BPF_PROG_TYPE_CGROUP_SYSCTL,
989 BPF_PROG_TYPE_RAW_TRACEPOINT_WRITABLE,
990 BPF_PROG_TYPE_CGROUP_SOCKOPT,
991 BPF_PROG_TYPE_TRACING,
992 BPF_PROG_TYPE_STRUCT_OPS,
993 BPF_PROG_TYPE_EXT,
994 BPF_PROG_TYPE_LSM,
995 BPF_PROG_TYPE_SK_LOOKUP,
996 BPF_PROG_TYPE_SYSCALL, /* a program that can execute syscalls */
997 BPF_PROG_TYPE_NETFILTER,
998 };insn:struct bpf_insn 数据结构体数组
1
2
3
4
5
6
772 struct bpf_insn {
73 __u8 code; /* opcode */
74 __u8 dst_reg:4; /* dest register */
75 __u8 src_reg:4; /* source register */
76 __s16 off; /* signed offset */
77 __s32 imm; /* signed immediate constant */
78 };insn_cnt:insn数组中的指令条数
license:license字符串
log_buf:指向调用者自行分配的一个缓冲区buff,这个缓冲区用来存放verifier的验证日志
log_size:log_buf的大小
log_level:如果为0表示不需要日志,这样log_buf必须指向NULL
我们只需要使用close(fd)就可以在内核当中卸载我们的eBPF程序,但是这里存在例外
An eBPF object is deallocated only after all file descriptors referring to the object have been closed.
2.eBPF程序类型
eBPF 程序类型 (prog_type) 决定了程序可以调用的内核辅助函数的子集。程序类型还决定了程序输入(上下文)——struct bpf_context 的格式(它是传递到 eBPF 程序中的数据 blob)第一个参数)。
以下是部分程序类型所对应的支持内核函数子集,注意这个子集在将来可能会扩充
1.BPF_PROG_TYPE_SOCKET_FILTER(since Linux 3.19)
- bpf_map_lookup_elem(map_fd, void *key)
- bpf_map_update_elem(map_fd, void *key, void *value)
- bpf_map_delete_elem(map_fd, void *key)
3.eBPF程序绑定
一旦某个eBPF程序被加载到内存当中,它可以被附加到某个事件上。不同的内核子系统有不同的附加方式。
从 Linux 4.1 开始,可以使用以下调用将文件描述符 prog_fd 引用的 eBPF 程序附加到创建的 perf 事件文件描述符 event_fd
1 | |
第四章:圣丹尼斯
1.汇编指令编写eBPF程序
这里我们开始使用我们的bpf系统调用来更加直观的感受一下eBPF的使用
在linux内核源码中 samples/bpf/bpf_insn.h文件提供了一系列内核工作人员为我们准备的指令模板方便我们使用。但一般在进行eBPF开发的时候会使用更加高效的工具,但这里只是进行一个简单的学习
1 | |
因此本次实验采用linux 6.7的内核,这里在配置编译选项的时候需要我们选中
General setup -> BPF subsystem -> Enable bpf() system call
-> Enable BPF Just In Time compiler
最好能取消掉
General setup -> BPF subsystem -> Disable Unprivileged BPF by Default
该选项会导致 /proc/sys/kernel/bpf/unprivileged_bpf_enabled默认为2,会使得现如今唯一允许Linux非特权用户加载的 BPF_PROG_TYPE_SOCKET_FILTER类型bpf程序加载失败
因此取消该选项并且保证上面的 /proc/sys/kernel/bpf/unprivileged_bpf_enabled文件为0才能正常使用该类型的bpf程序.
我们使用上面的BPF指令宏定义来写两条指令,分别是给寄存器赋值和一个结尾的EXIT指令
1 | |
这里我们将日志等级设为最高,然后打印日志即可

2.使用libbpf-bootstrap来编写eBPF程序
使用linux内核所提供的宏来编写eBPF程序终究是繁琐的,并且不知如何来调用功能丰富的eBPF-helpers函数,因此我们使用libbpf来帮助我们编写eBPF程序
这里推荐一个github项目,在方便我们编写程序的同时也提供了许多例子供我们学习
https://github.com/libbpf/libbpf-bootstrap.git
项目中几个对于其他项目的引用,因此我们需要在clone的仓库中使用下面的指令
1 | |
然后我们可以直接开始通过该项目的README来进行学习
$\alpha$.minimal
该程序是一个简单的学习例子,他并不需要BPF CO-RE,他安装了一个每秒都会触发一次的tracepoint handler.并且使用BPF帮助函数bpf_printk来交互.我们可以通过查看文件/sys/kernel/debug/tracing/trace_pipe来观察他的输出
首先我们就来简简单单看个效果


那该程序到底做了些什么呢,我们现在来分析程序中的代码
BPF侧
该项目使用*.bpf.c来表示该测试程序中BPF侧的代码
所以我们直接查看minimal.bpf.c
1 | |
linux/bpf.h:该文件包含了内核端BPF程序一些所需要的类型和常量bpf/bpf-helpers.h:该文件由libbpf所提供,包含最常用的宏、常量和 BPF 帮助器定义,几乎每个现有的 BPF 应用程序都会使用它们。上面的bpf_get_current_pid_tgid()是此类 BPF 助手的示例LICENSE: 变量定义 BPF 代码的许可证。指定许可证是强制性的,并且由内核强制执行。某些 BPF 功能对于非 GPL 兼容代码不可用。请注意特殊的SEC("license")注释SEC():(由bpf_helpers.h提供)将变量和函数放入指定的部分。SEC("license")以及其他一些部分名称是libbpf规定的约定,因此请确保遵守它.SEC("tp/syscalls/sys_enter_write") int handle_tp(void *ctx) { ... }:该定义将被加载到内核中的 BPF 程序。它在专门命名的部分中表示为普通 C 函数(使用SEC()宏)。节名称定义了 libbpf 应创建什么类型的 BPF 程序以及如何/将其附加到内核中的位置。在本例中,我们定义了一个跟踪点 BPF 程序,每次从任何用户空间应用程序调用write()系统调用时都会调用该程序。handle_tp:即为tracepoint程序的处理函数,bpf_get_current_pid_tgid返回值的高 32 位中的 PID(或内部内核术语中的“TGID”)。然后它检查触发write()系统调用的进程是否是我们的minimal进程。这对于繁忙的系统来说非常重要,因为很可能许多不相关的进程都会发出write(),这使得按照您自己的方式试验您自己的 BPF 代码变得非常困难。my_pid全局变量将使用下面用户空间代码中minimal进程的实际 PID 进行初始化。bpf_printk:该函数来自于bpf_helpers,他相当于BPF程序当中的printf,只不过他将字符串会输出到trace_pipe文件当中
用户侧
minimal.c
1 | |
首先该文件包含了一个minimal.skel.h文件,它是由Makefile在编译过程中使用bpftool生成的,其中包括minimal.bpf.c的代码框架,因此只需要在用户端程序中包含该编译好的bpf程序骨架即可成功运行,下面是minimal.bpf.c的高级框架表示
1 | |
它具有可以传递给 libbpf API 函数的 struct bpf_object *obj; 。它还具有 maps 、 progs 和 links “部分”,可直接访问 BPF 代码中定义的 BPF 映射和程序(例如 handle_tp BPF 程序)。这些引用可以直接传递到 libbpf API,以使用 BPF 映射/程序/链接执行额外操作。 Skeleton 还可以选择具有 bss 、 data 和 rodata 部分,允许从用户空间直接(不需要额外的系统调用)访问 BPF 全局变量。在本例中,我们的 my_pid BPF 变量对应于 bss->my_pid 字段。
然后我们回过头来查看我们bpf用户侧的代码,先从main函数开始看起
1 | |
其中libbpf_set_print函数为所有libpf日志提供自定义回调函数,这里是用户自定的仅输出错误的日志函数,我们可以发现在libbpf下的bpf_helper.c函数中也同该libbpf_print_fn大差不差
这里在minimal的情况下他仅仅将所有日志都发送给标准错误,然后我们接着向下分析
1 | |
这里调用了通过 minimal.skel.h文件中所定义的函数minimal_bpf__open,他实际上是一个wrapper,调用了 minimal_bpf__open_opts(NULL)
1 | |
然后调用 minimal_bpf__create_skeleton函数来搭建框架,主要是填满下面这个结构体
1 | |
然后调用bpf_object__open_skeleton函数
1 | |
第五章:瓜玛
本章节来讲一讲eBPF几种程序类型的一个基础知识,分别是kprobe,uprobe,tracepoint
本章节内容大部分来自对于官方文档的学习
1.Kprobe
1.概念
Kprobe允许我们可以动态的在内核运行过程中打上断点,并且可以搜集这些调试信息.我们甚至几乎可以对任何内核代码地址进行跟踪调试(有一些内核代码无法被追踪,他被维护成一个黑名单,可以查看kprobes_blacklist)
存在两种probes:kprobes和kretprobes(后面也被叫做return probes),一个kprobe几乎能插入到内核中的任何指令当中.一个return probe只有在指定的函数返回时才会其作用
在典型的例子当中,基于kprobes的指令被打包成一个内核模块,该模块的init函数安装(或者说叫注册)了一个或多个probes,并且在exit函数当中卸载他们.一个注册函数诸如register_kprobe()指定了该probe插入到那里并且当该probe被命中会调用哪个handler
在下面几个章节来介绍kprobe的工作原理,如果您迫切要立即使用kprobes,那么可以去查看kprobe_archs_supported文档
2.Kprobe工作原理
当一个kprobe被注册,Kprobe复制被插桩的指令然后使用一个断点指令来替换该指令的开头几个字节(例如在i386或者说x86_64上的int3中断指令)
当cpu命中该断点指令时,陷阱触发,cpu的寄存器们就被保存并且控制权通过notifier_call_chain机制传递给Kprobes.Kprobes执行与kprobe所关联的pre_handler,然后将kprobe结构体的地址和保存到的寄存器传递给handler.
下一步,Kprobes单步执行复制的被插桩的指令,在单步执行指令之后,Kprobes 执行与 kprobe 关联的“post_handler”(如果有)。然后继续执行探测点之后的指令。